Learn to Query and Visualize anything: CSV/Text/Excel/JSON/TSV/Avro/videos/Images/Parquet/NoSQL/SQL Databases etc
https://github.com/apache/drill
Schema-free SQL Query Engine for Hadoop, NoSQL and Cloud Storage
Agility
Get faster insights without the overhead (data loading, schema creation and maintenance, transformations, etc.)
Flexibility
Analyze the multi-structured and nested data in non-relational datastores directly without transforming or restricting the data
Familiarity
Leverage your existing SQL skillsets and BI tools including Tableau, Qlikview, MicroStrategy, Spotfire, Excel and more
Query any non-relational datastore (well, almost…)
Drill supports a variety of NoSQL databases and file systems, including HBase, MongoDB, MapR-DB, HDFS, MapR-FS, Amazon S3, Azure Blob Storage, Google Cloud Storage, Swift, NAS and local files. A single query can join data from multiple datastores. For example, you can join a user profile collection in MongoDB with a directory of event logs in Hadoop.
Drill’s datastore-aware optimizer automatically restructures a query plan to leverage the datastore’s internal processing capabilities. In addition, Drill supports data locality, so it’s a good idea to co-locate Drill and the datastore on the same nodes.
https://github.com/apache/superset
Superset is fast, lightweight, intuitive, and loaded with options that make it easy for users of all skill sets to explore and visualize their data, from simple line charts to highly detailed geospatial charts.
Powerful yet easy to use
Superset makes it easy to explore your data, using either our simple no-code viz builder or state-of-the-art SQL IDE.
Integrates with modern databases
Superset can connect to any SQL-based databases including modern cloud-native databases and engines at petabyte scale.
Modern architecture
Superset is lightweight and highly scalable, leveraging the power of your existing data infrastructure without requiring yet another ingestion layer.
Rich visualizations and dashboards
Superset ships with 40+ pre-installed visualization types. Our plug-in architecture makes it easy to build custom visualizations.
Overview
Sub-second queries at any scale
Execute OLAP queries in milliseconds on high-cardinality and high-dimensional data sets with billions to trillions of rows without pre-defining or caching queries in advance.
High concurrency at the lowest cost
Build real-time analytics applications that supports 100s to 100,000s queries per second at consistent performance with a highly efficient architecture that uses less infrastructure than other databases.
Real-time and historical insights
Unlock streaming data potential through Druid’s native integration with Apache Kafka and Amazon Kinesis as it supports query-on-arrival at millions of events per second, low latency ingestion, and guaranteed consistency.® Druid
A high performance, real-time analytics database that delivers sub-second queries on streaming and batch data at scale and under load.
Key Druid Features
Interactive Query Engine
Druid utilizes scatter/gather for high speed queries with data preloaded into memory or local storage to avoid data movement and network latency.
Tiering & QoS
Configurable tiering with quality of service enables the ideal price-performance for mixed workloads, guarantees priority, and avoids resource contention.
Optimized Data Format
Ingested data is automatically columnarized, time-indexed, dictionary-encoded, bitmap-indexed, and type-aware compressed.
Elastic Architecture
Loosely coupled components for ingestion, queries, and orchestration combined with a deep storage layer enable easy & quick scale-up & scale-out.
True Stream Ingestion
A connector-free integration with streaming platforms enables query-on-arrival, high scalability, low latency, and guaranteed consistency.
Non-stop Reliability
Automatic data services including continuous backup, automated recovery, and multi-node replication ensure high availability and durability.
Schema Auto-Discovery
Druid can automatically detect, define, and update column names and data types upon ingestion, providing the ease of schemaless and the performance of strongly typed schemas.
Flexible Joins Support
Druid supports join operations during data ingestion and at query-time execution, with the fastest query performance when tables are pre-joined during ingestion.
SQL Support
Developers and analysts can easily use the familiar SQL API for end-to-end data operations across ingestion, transformation, and querying.
Lets get started:
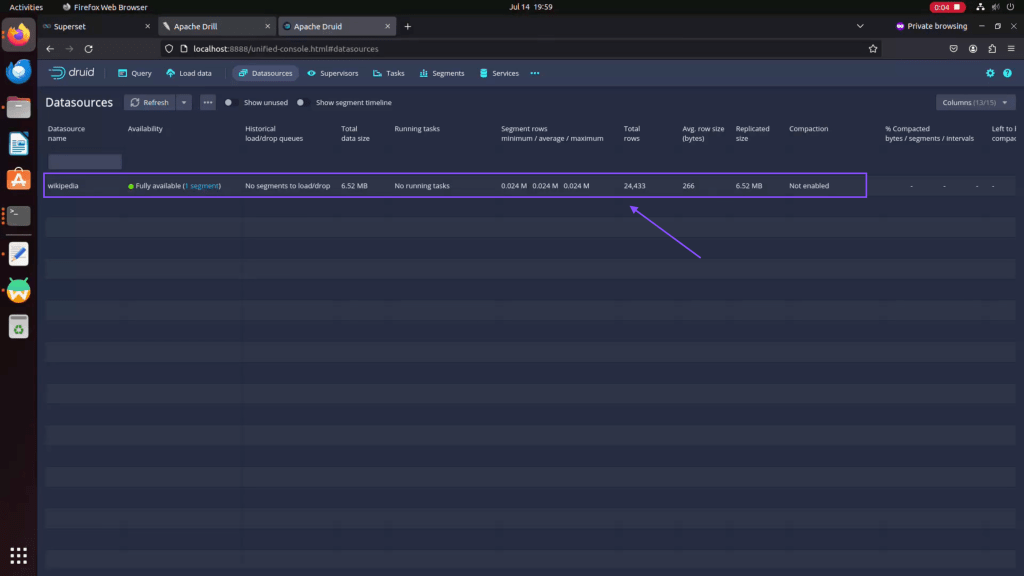
Step 01: Make sure that Apache druid up and running with loaded dataset.
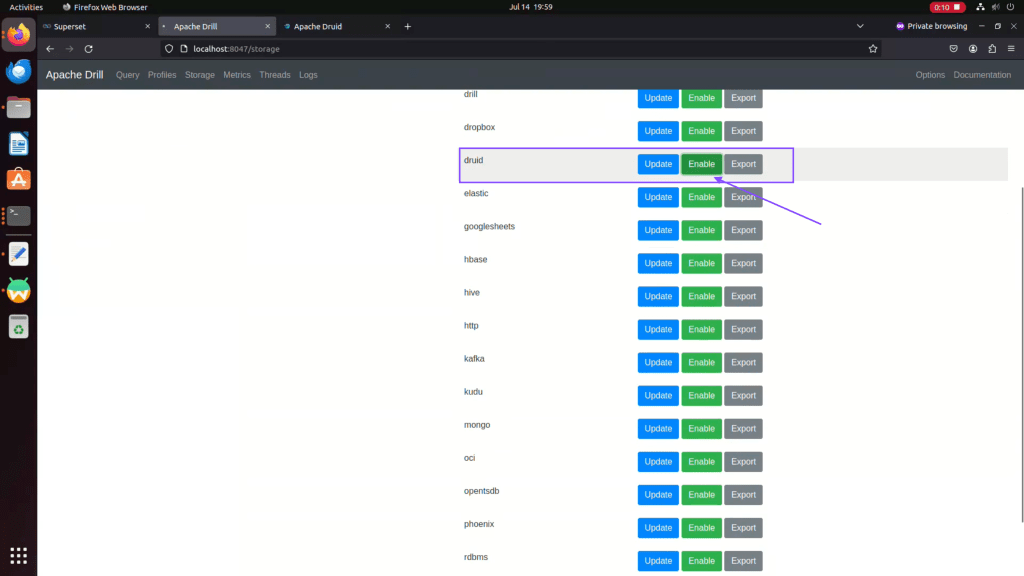
Step 02: Enable Apache Druid Plugin in Apache Drill Web-UI storage plugin
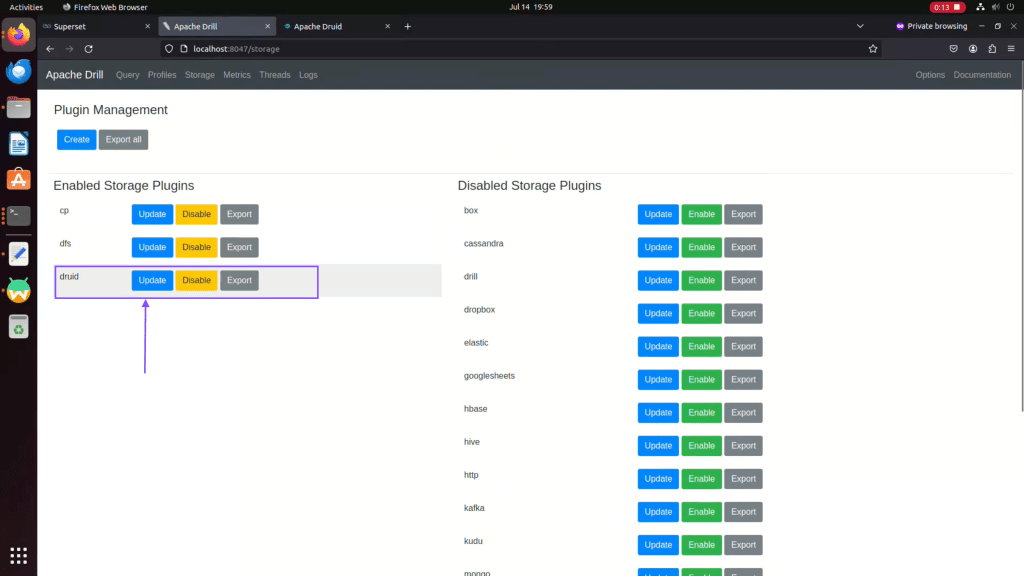
Step 03: Click on Update Apache Druid Plugin.
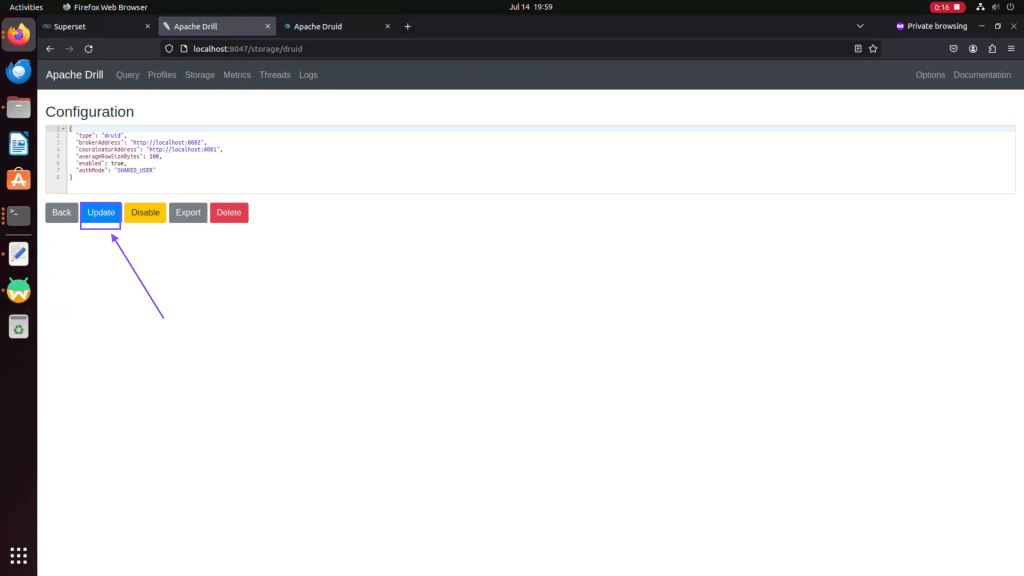
Step 04: Update Apache Druid Configuration and go back to apache superset ui
Step 05: Got to SQL Lab
Step 06: Under Apache Drill, Choose Druid Schema
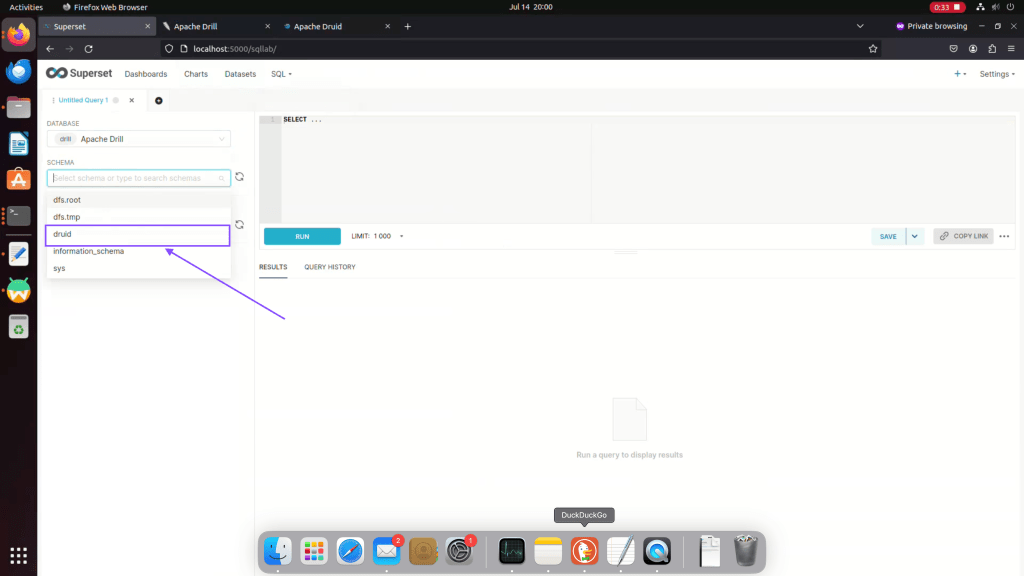
Step 07: Under Druid Schema click on Table schema to view data.
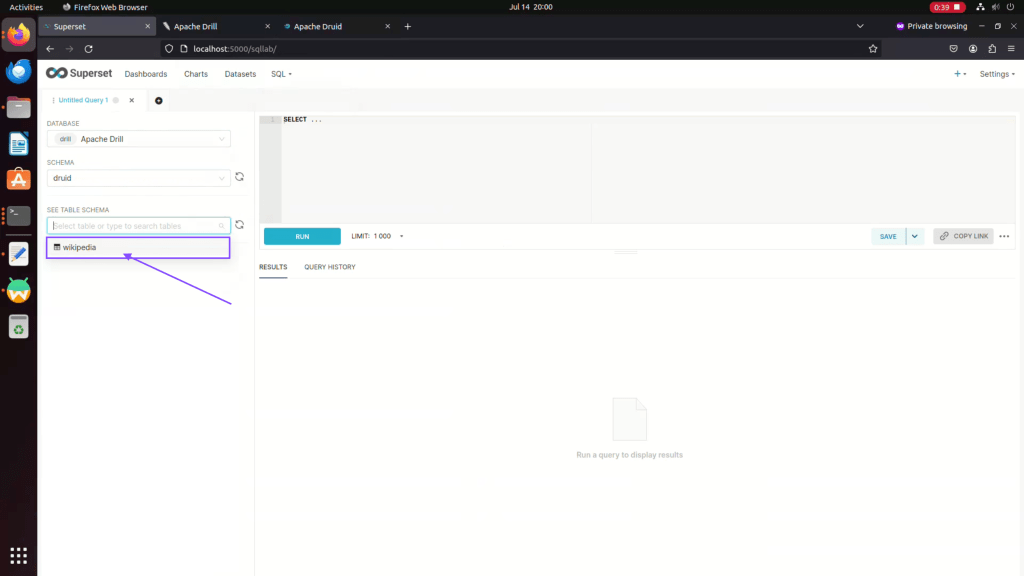
Step 08: Here data will be displayed to table schema
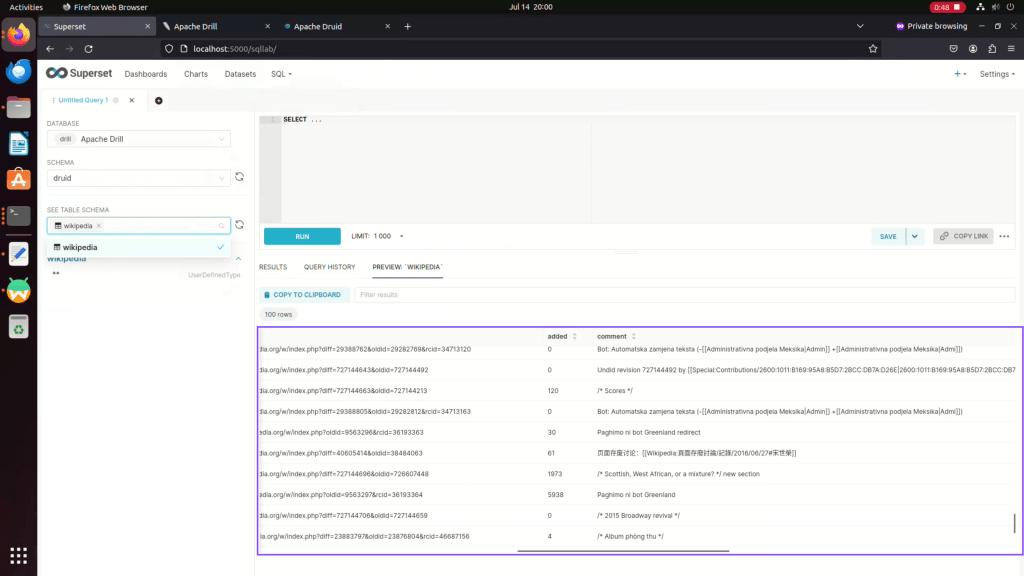
Step 09: Now run custom SQL query on Druid Data source as show below
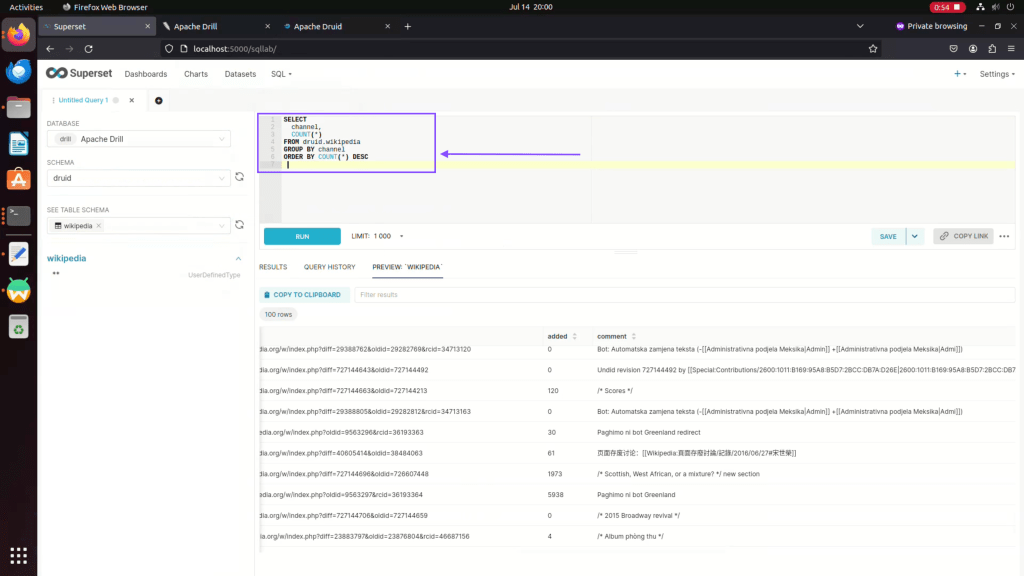
Step 10: Click on create chart to visualize your query data.
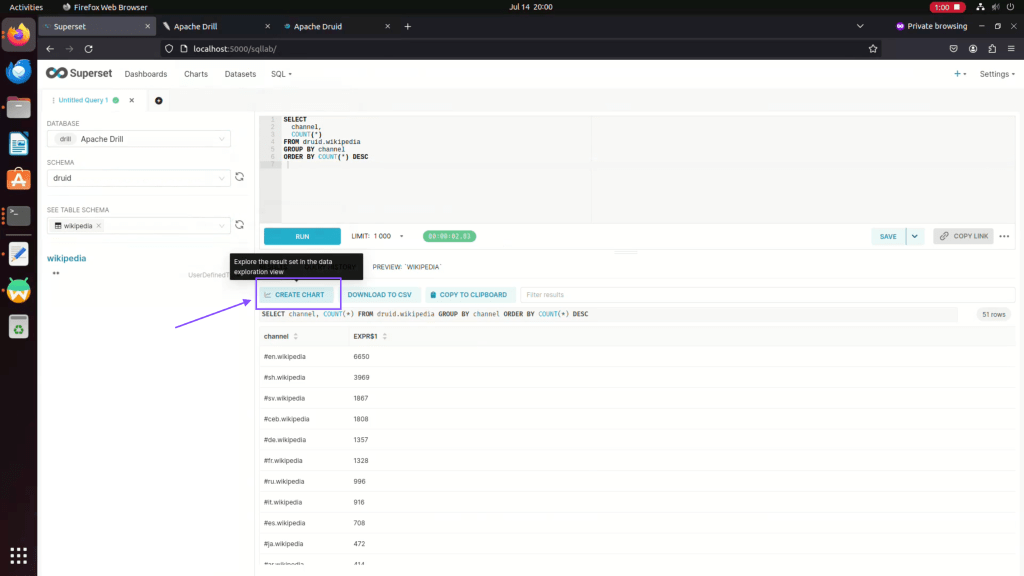
Step 11: Click on View all charts to select your chart for visualization

Step 12: Click on Funnel or Other chart as per your requirement
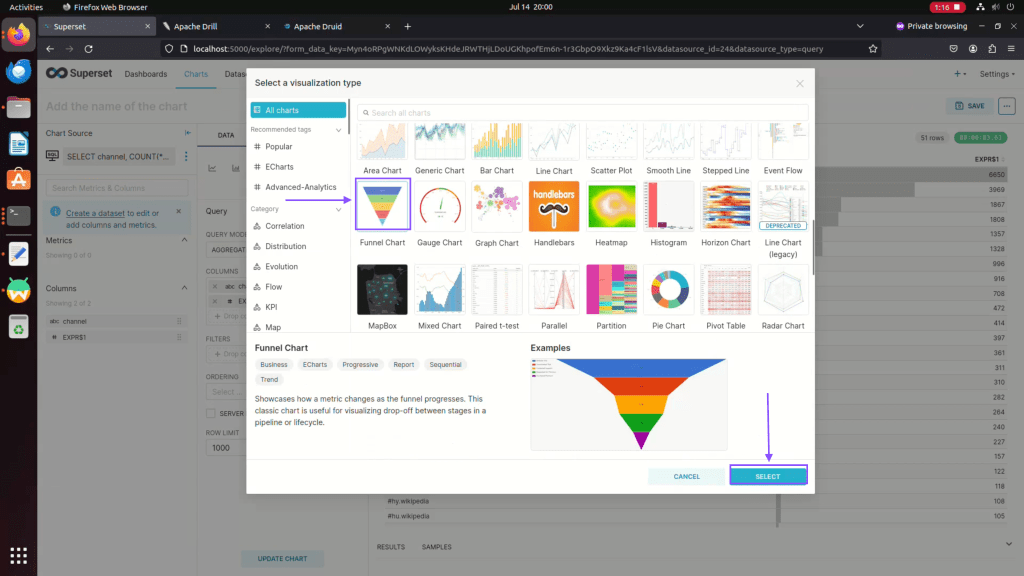
Step 13: Drag and Drop Column into metric for values
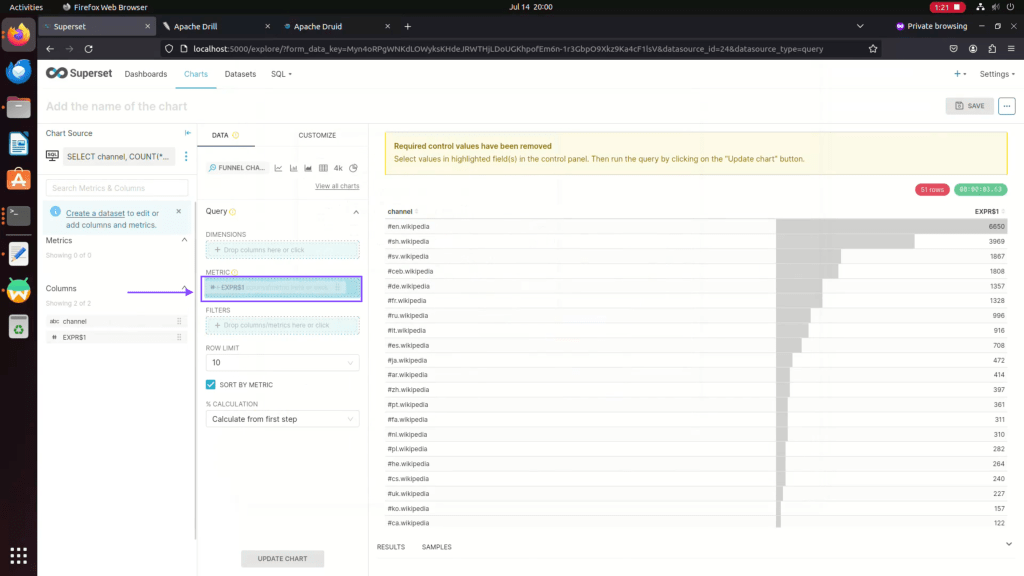
Step 14: Drag and drop columns to dimensions
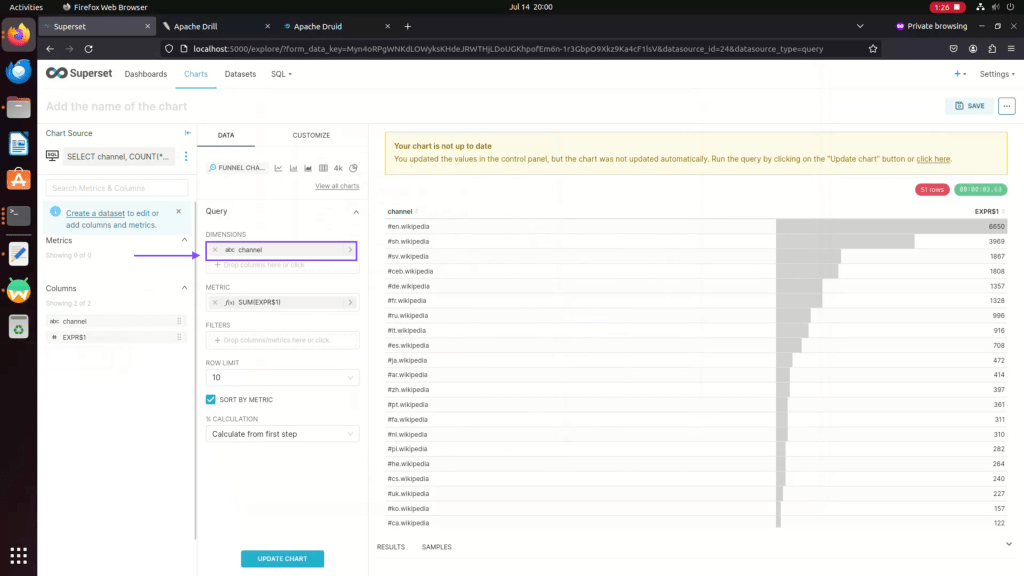
Step 15: Click on Customise tab to customize the chart.
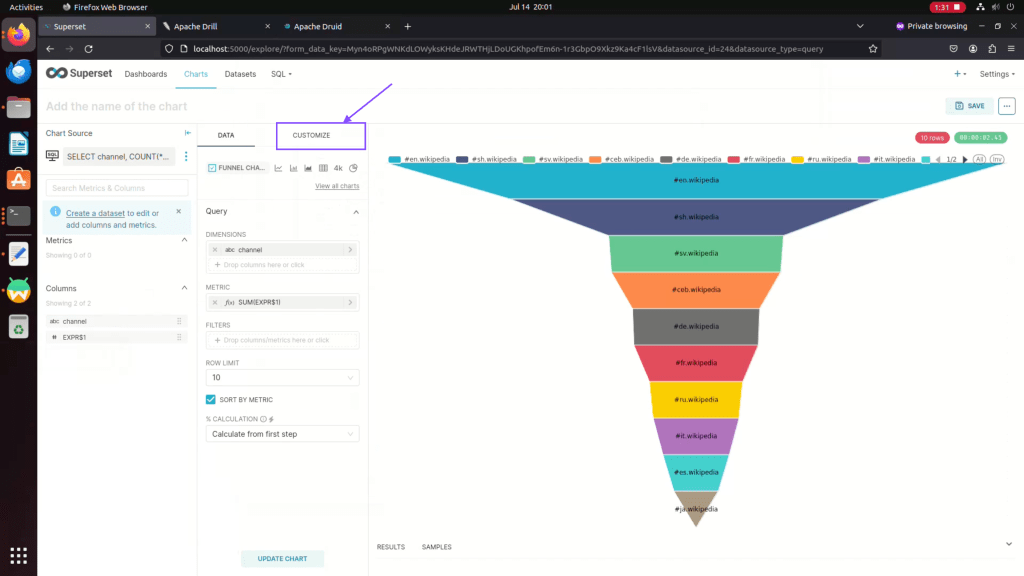
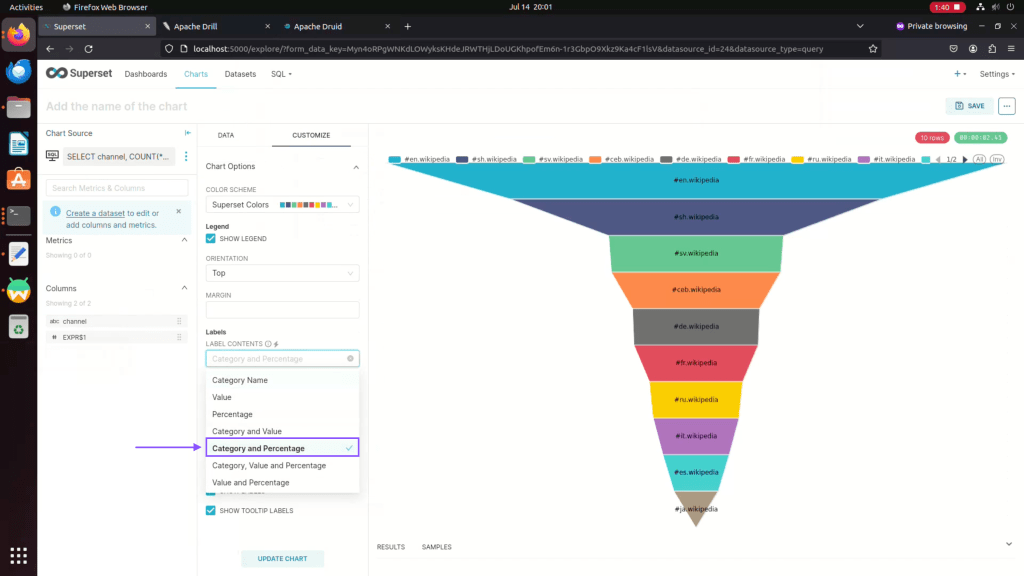
Step 16: Choose Labels for your charts.
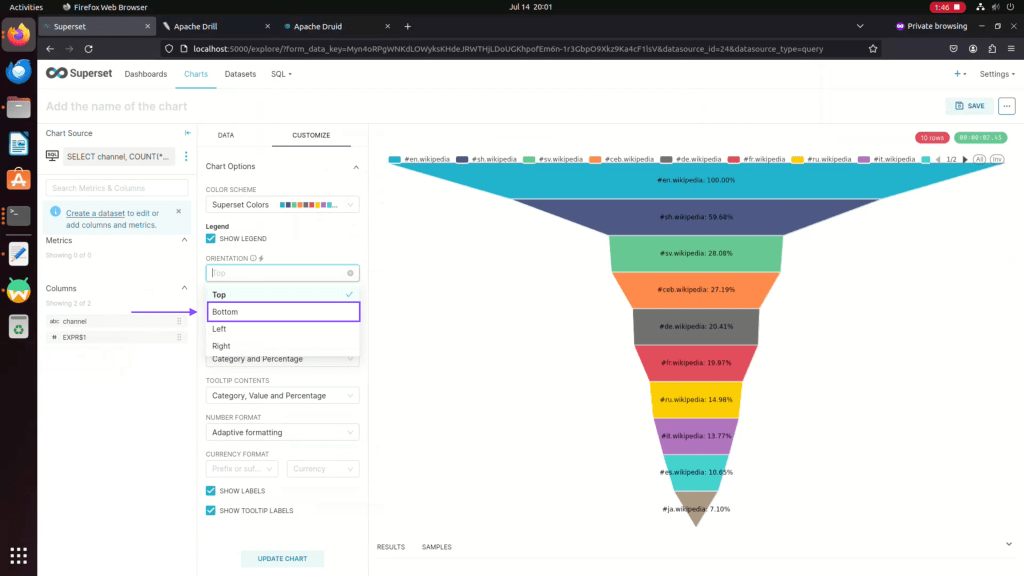
Step 17: Choose legend orientation
Step 18: Click on save
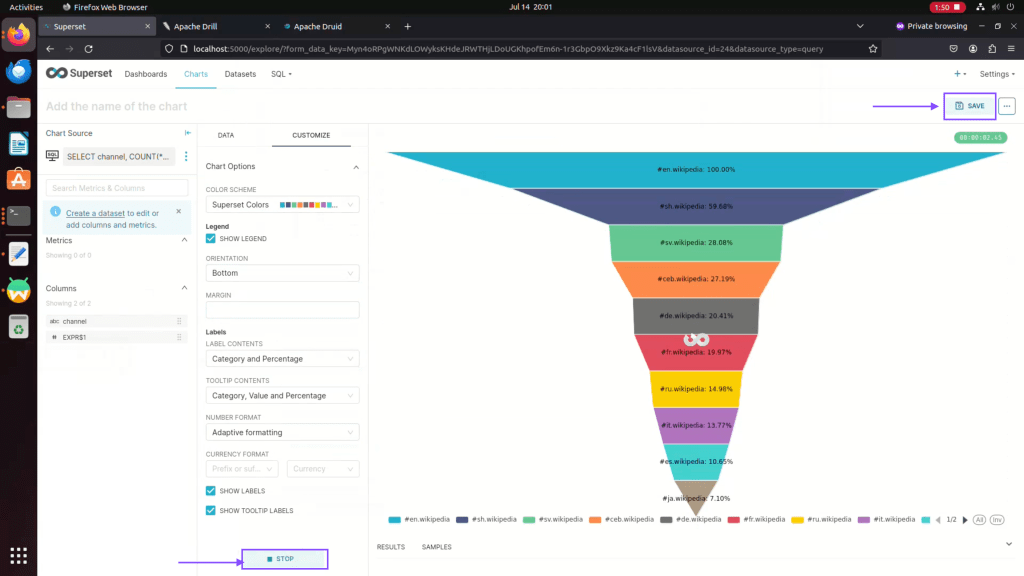
Step 19: Enter Chart name, Dataset name, and dashboard name and then click on “save and go to dashboard”
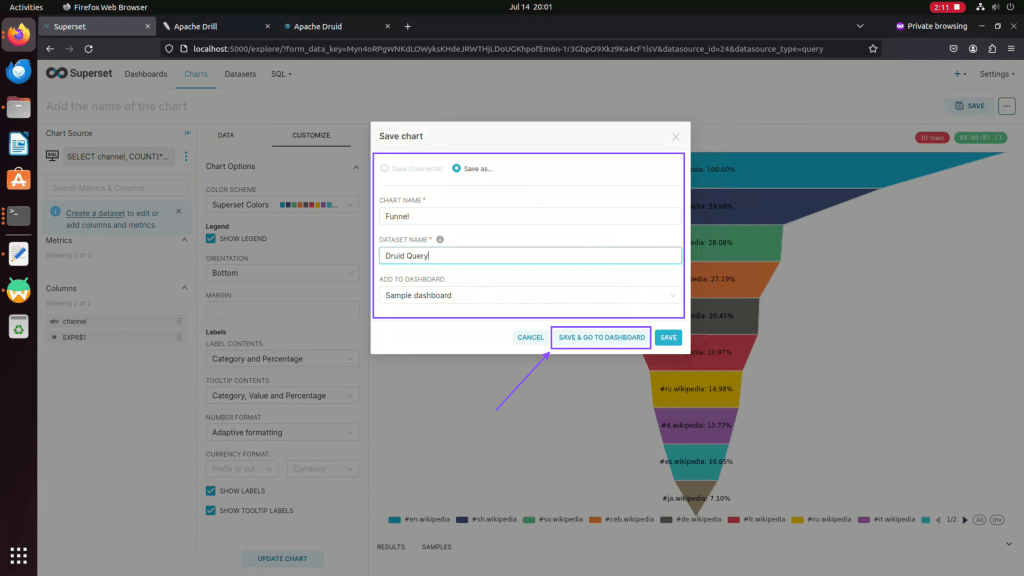
Step 20: Click on edit dashboard
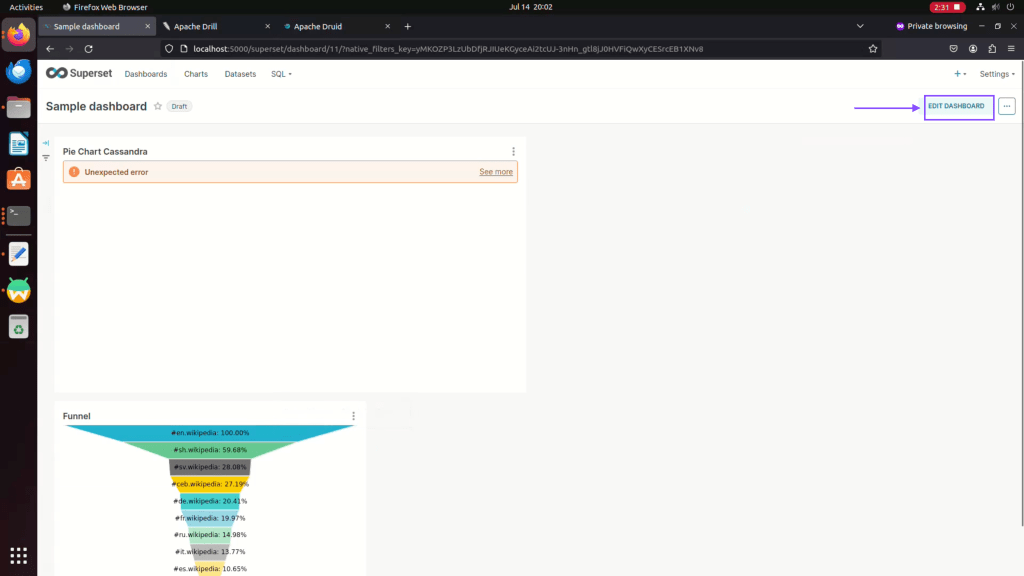
Step 21: Drag and drop your chart as per your preferred layout.

Step 22: Click on save to update dashboard.
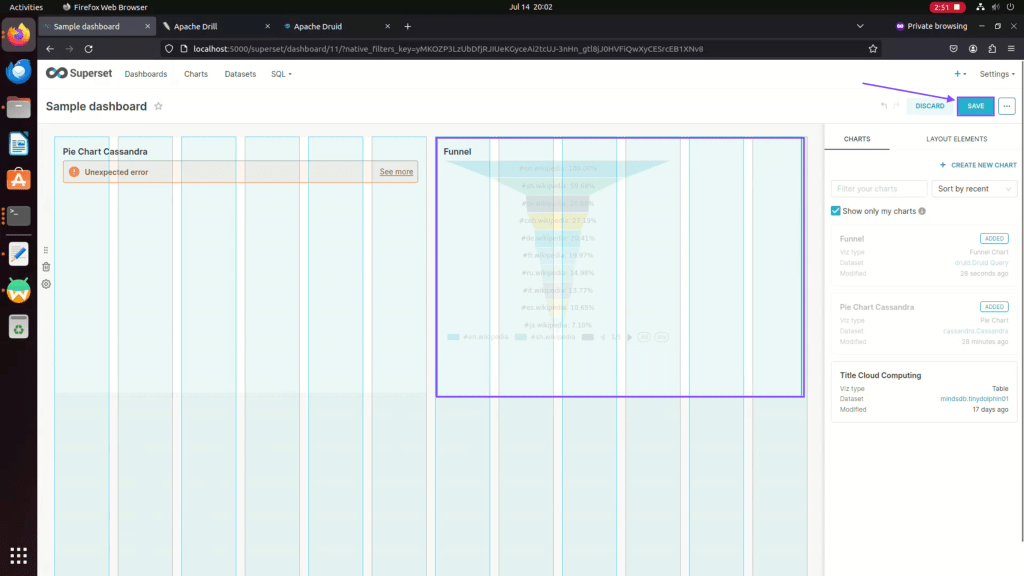
Step 23: Here is the updated dashboard.
Here is youtube video for visual reference.

You must be logged in to post a comment.