Learn to Query and Visualize anything: CSV/Text/Excel/JSON/TSV/Avro/videos/Images/Parquet/NoSQL/SQL Databases etc
https://github.com/apache/drill
Schema-free SQL Query Engine for Hadoop, NoSQL and Cloud Storage
Agility
Get faster insights without the overhead (data loading, schema creation and maintenance, transformations, etc.)
Flexibility
Analyze the multi-structured and nested data in non-relational datastores directly without transforming or restricting the data
Familiarity
Leverage your existing SQL skillsets and BI tools including Tableau, Qlikview, MicroStrategy, Spotfire, Excel and more
Query any non-relational datastore (well, almost…)
Drill supports a variety of NoSQL databases and file systems, including HBase, MongoDB, MapR-DB, HDFS, MapR-FS, Amazon S3, Azure Blob Storage, Google Cloud Storage, Swift, NAS and local files. A single query can join data from multiple datastores. For example, you can join a user profile collection in MongoDB with a directory of event logs in Hadoop.
Drill’s datastore-aware optimizer automatically restructures a query plan to leverage the datastore’s internal processing capabilities. In addition, Drill supports data locality, so it’s a good idea to co-locate Drill and the datastore on the same nodes.
https://github.com/apache/superset
Superset is fast, lightweight, intuitive, and loaded with options that make it easy for users of all skill sets to explore and visualize their data, from simple line charts to highly detailed geospatial charts.
Powerful yet easy to use
Superset makes it easy to explore your data, using either our simple no-code viz builder or state-of-the-art SQL IDE.
Integrates with modern databases
Superset can connect to any SQL-based databases including modern cloud-native databases and engines at petabyte scale.
Modern architecture
Superset is lightweight and highly scalable, leveraging the power of your existing data infrastructure without requiring yet another ingestion layer.
Rich visualizations and dashboards
Superset ships with 40+ pre-installed visualization types. Our plug-in architecture makes it easy to build custom visualizations.
https://github.com/apache/cassandra
https://cassandra.apache.org/_/index.html
What is Apache Cassandra?
Apache Cassandra is an open source NoSQL distributed database trusted by thousands of companies for scalability and high availability without compromising performance. Linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect
platform for mission-critical data.
Hybrid
Masterless architecture and low latency means Cassandra will withstand an entire data center outage with no data loss—across public or private clouds and on-premises.
Fault Tolerant
Cassandra’s support for replicating across multiple datacenters is best-in-class, providing lower latency for your users and the peace of mind of knowing that you can survive regional outages. Failed nodes can be replaced with no downtime.
Focus on Quality
To ensure reliability and stability, Cassandra is tested on clusters as large as 1,000 nodes and with hundreds of real world use cases and schemas tested with replay, fuzz, property-based, fault-injection, and performance tests.
Performant
Cassandra consistently outperforms popular NoSQL alternatives in benchmarks and real applications, primarily because of fundamental architectural choices.
You’re In Control
Choose between synchronous or asynchronous replication for each update. Highly available asynchronous operations are optimized with features like Hinted Handoff and Read Repair
Security and Observability
The audit logging feature for operators tracks the DML, DDL, and DCL activity with minimal impact to normal workload performance, while the fqltool allows the capture and replay of production workloads for analysis.
Distributed
Cassandra is suitable for applications that can’t afford to lose data, even when an entire data center goes down. There are no single points of failure. There are no network bottlenecks. Every node in the cluster is identical.
Scalable
Read and write throughput both increase linearly as new machines are added, with no downtime or interruption to applications.
Elastic
Cassandra streams data between nodes during scaling operations such as adding a new node or datacenter during peak traffic times. Zero Copy Streaming makes this up to 5x faster without vnodes for a more elastic architecture particularly in cloud and Kubernetes environments
Lets get started:
Step 01: Click on storage in Apache Drill webui available at localhost:8047

Step 02: Enable Apache Cassandra Storage Plugin

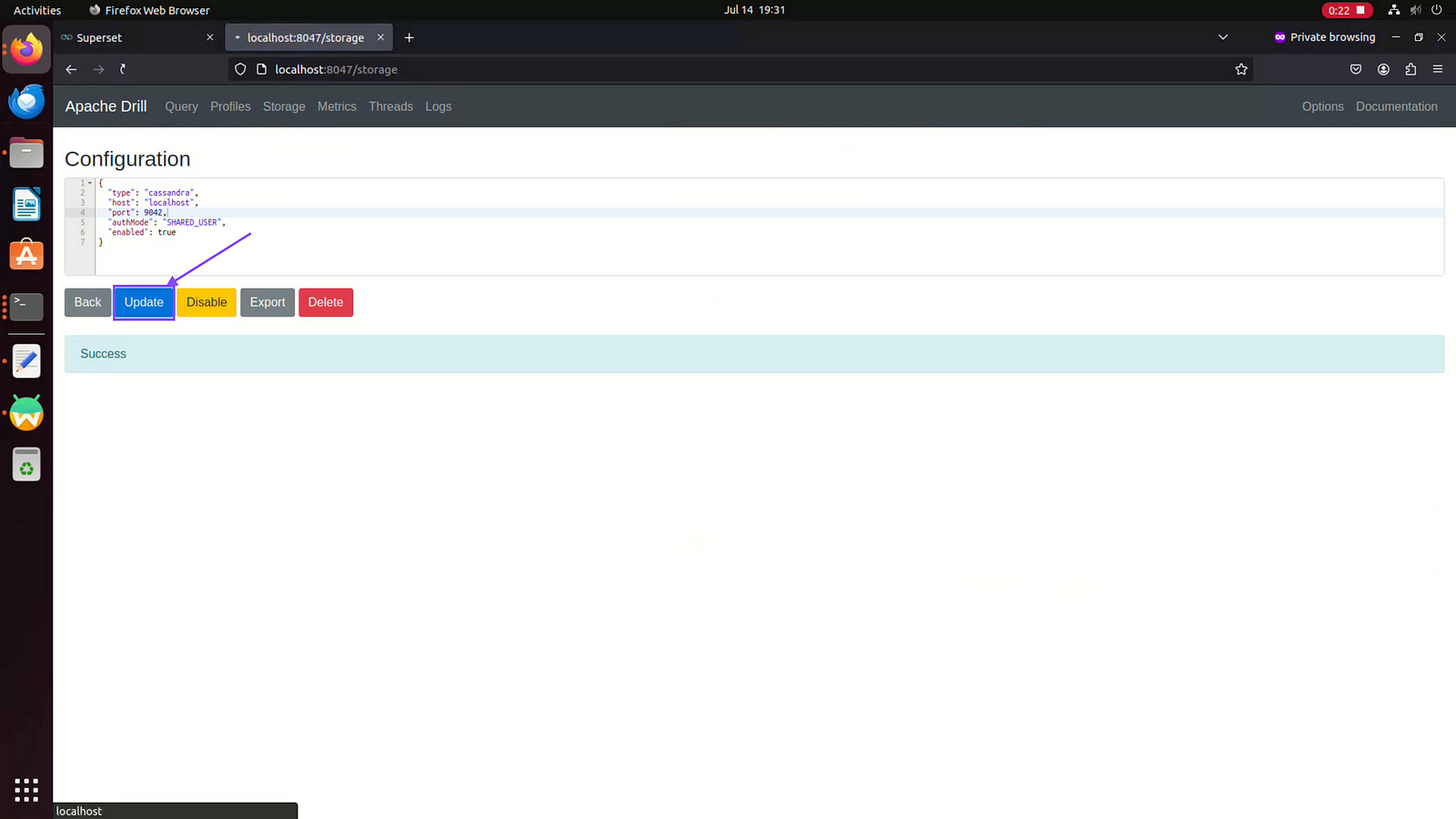
Step 03: Click on Update button after Enabling Storage plugin

Step 04: You can keep default configuration if it is on premise and development environment else change the configuration to match your requirement.

Step 05: Click on Update, if there is no error then you will get success message.
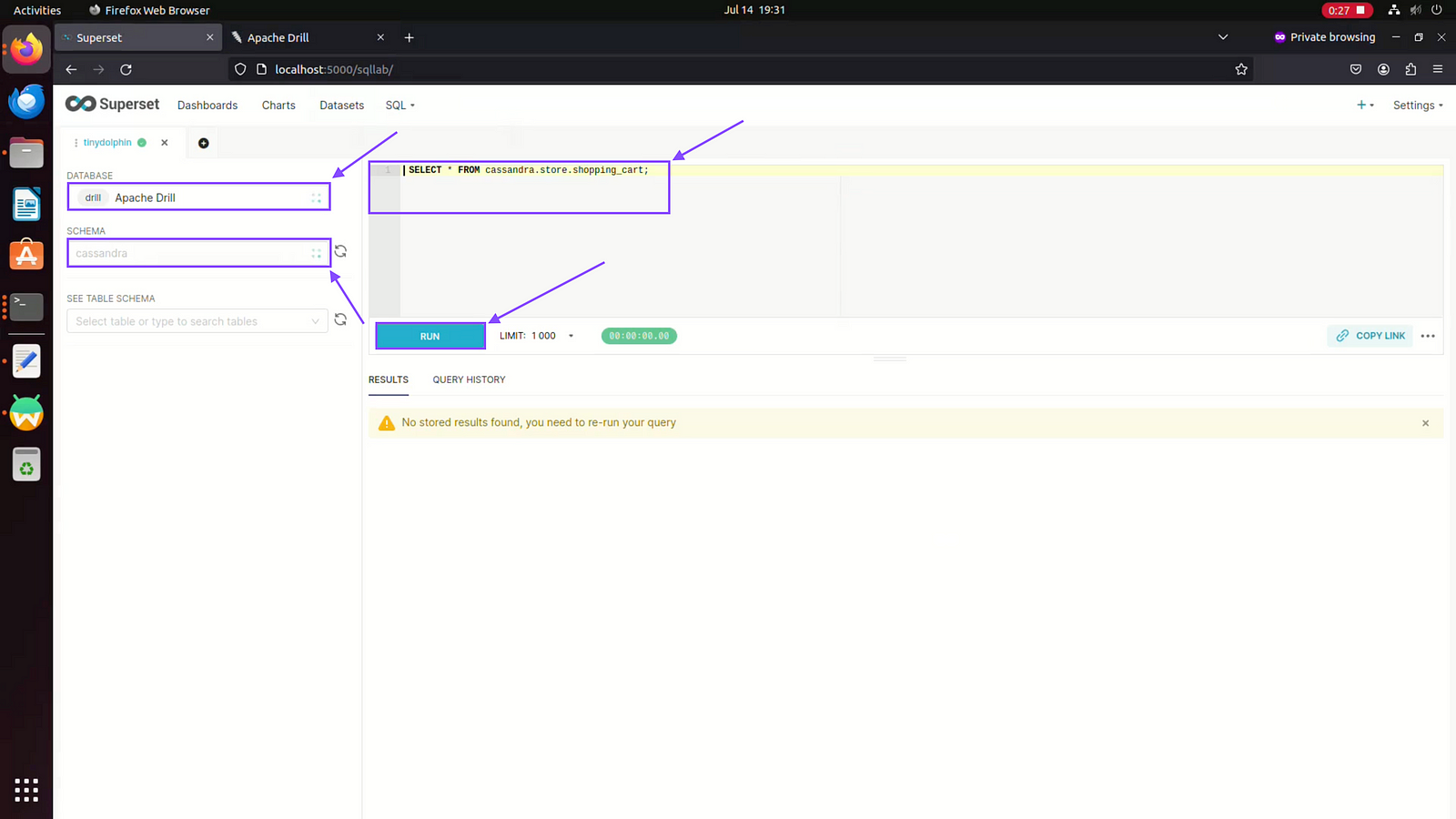
Step 06: Click on SQL Lab

Step 07: Now Click on Apache Drill database and Then choose schema as Apache Cassandra and write SQL Query to get data displayed.
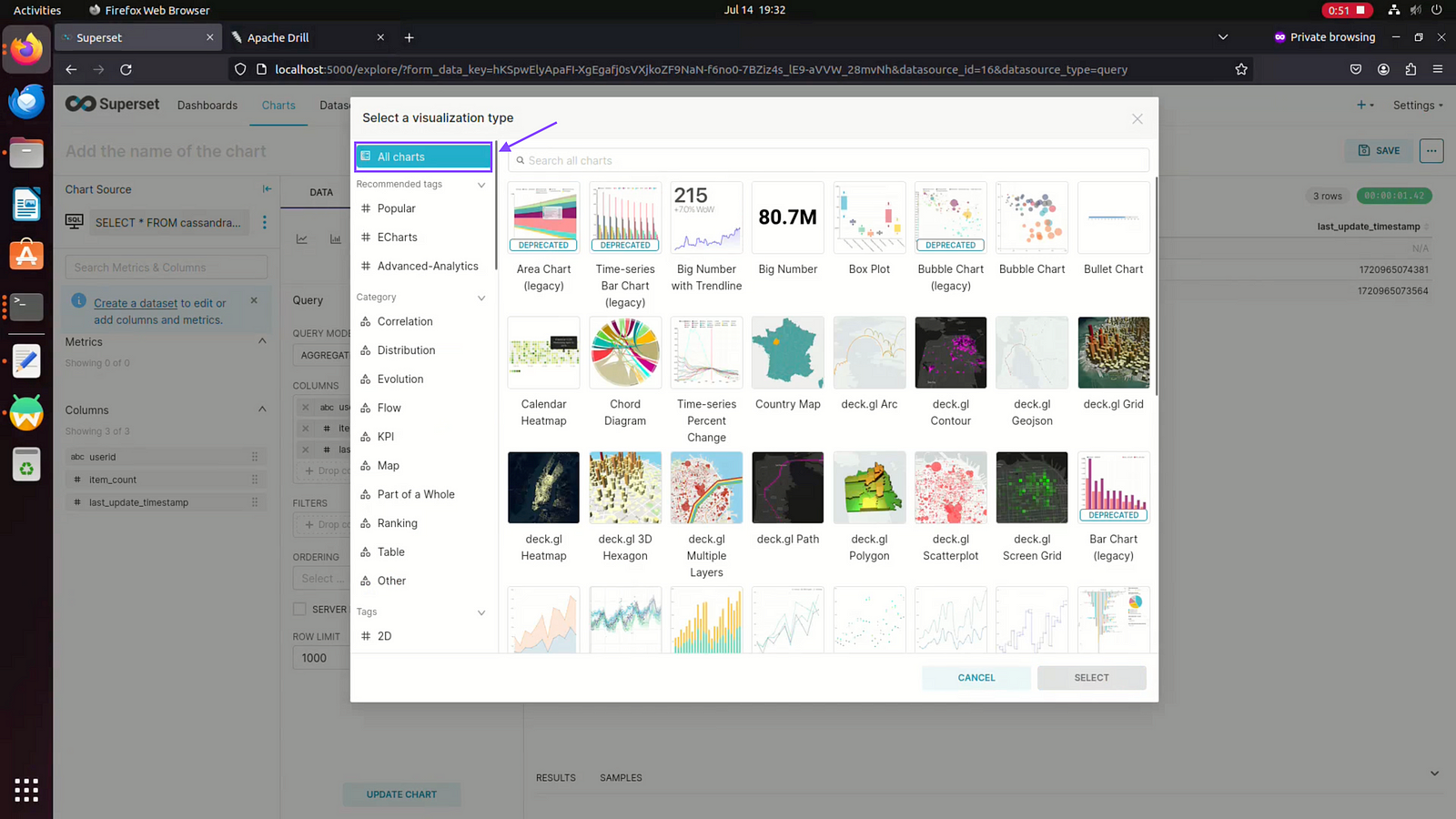
Step 08: Click on Create Chart to Visualize Apache Cassandara Data

Step 09: Click on View All Charts

Step 10: Click on All charts
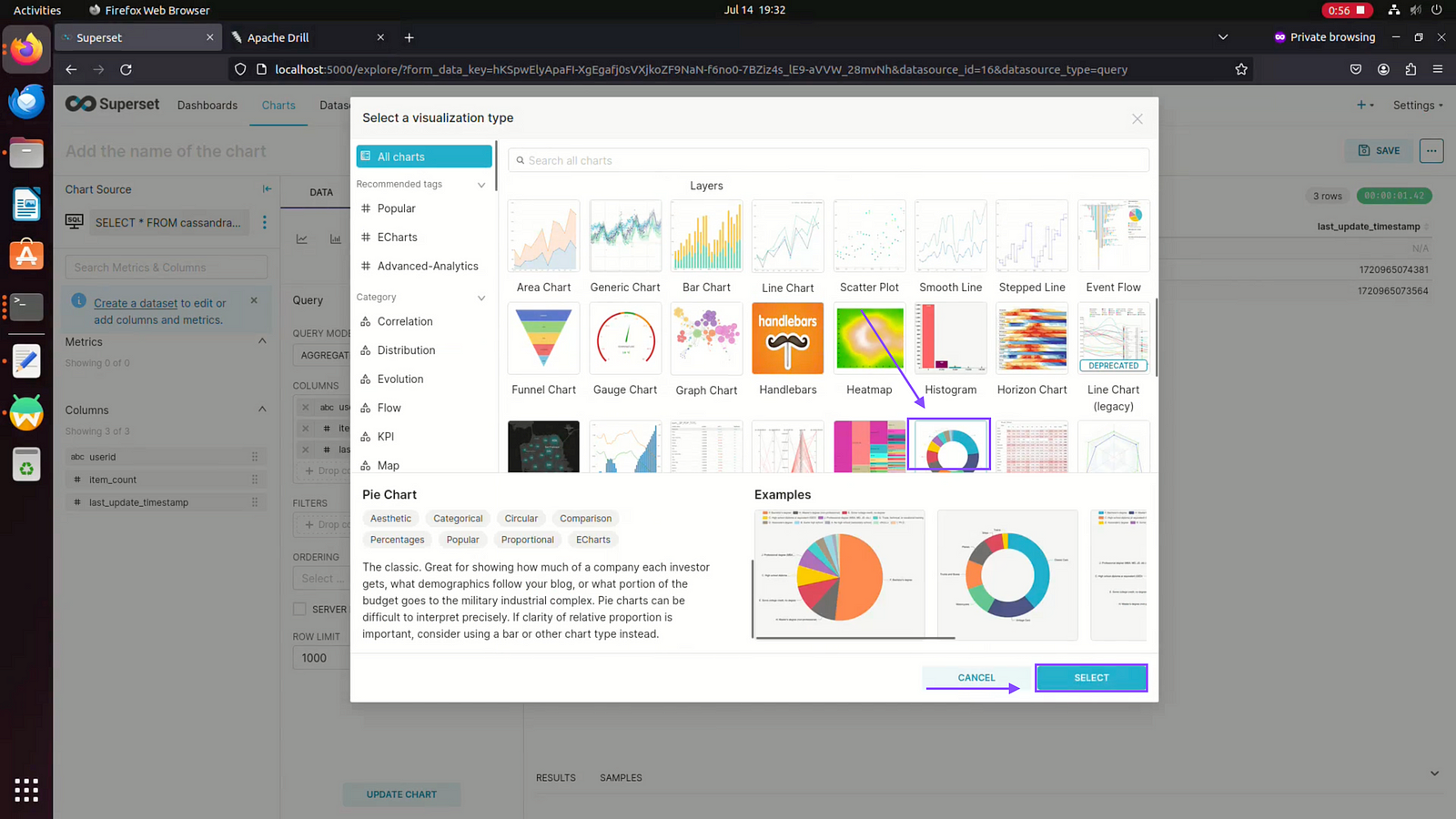
Step 11: Click on Pie chart or Other chart and then click on select.
Step 12: Drag and Drop dimensions by which you want to visualize values

Step 13: Drag and drop values on metrics and choose (Sum/Count/Avg. etc)

Step 14: In Customize section choose chart colour options
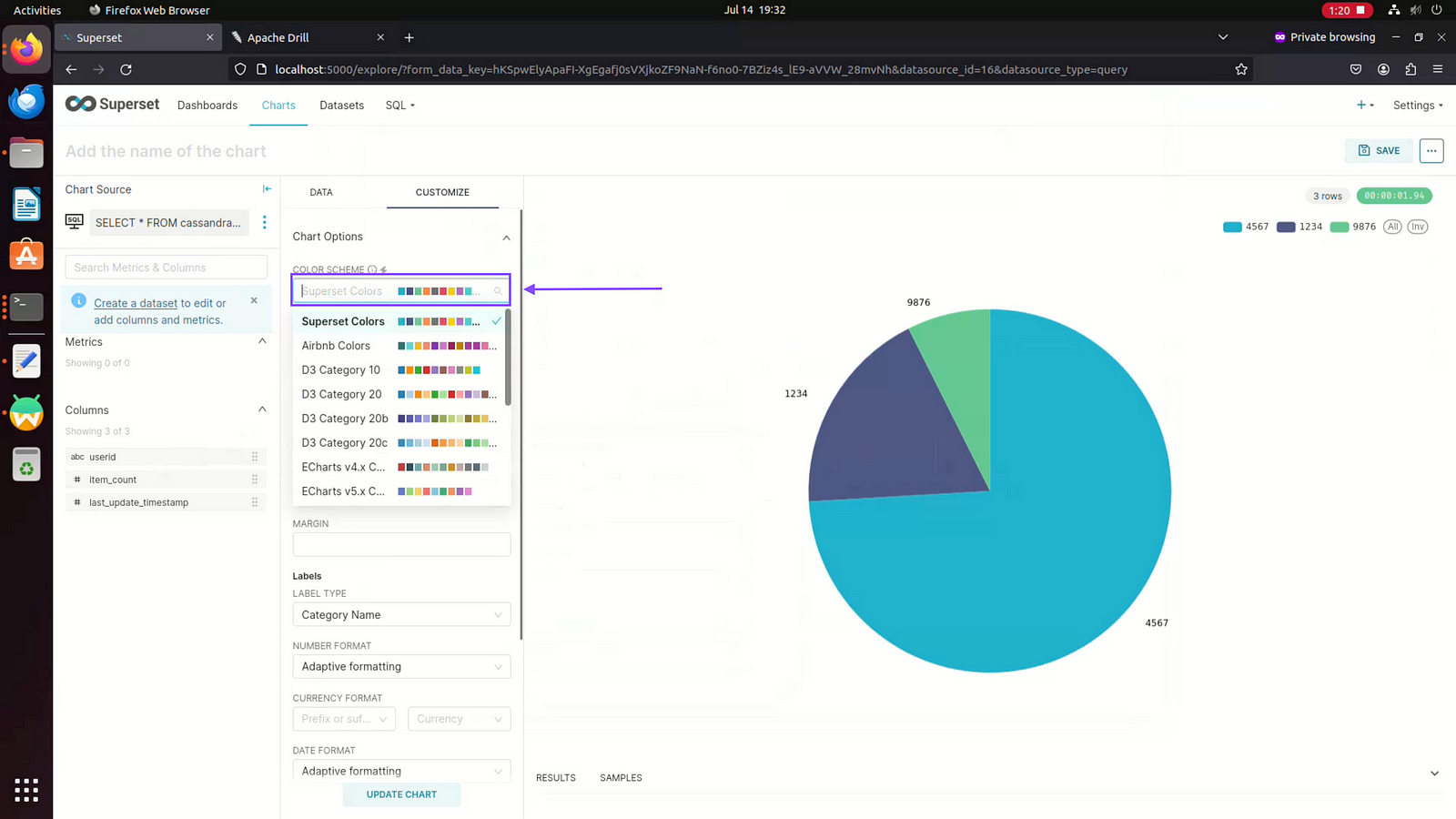
Step 15: Choose label types for Pie Chart

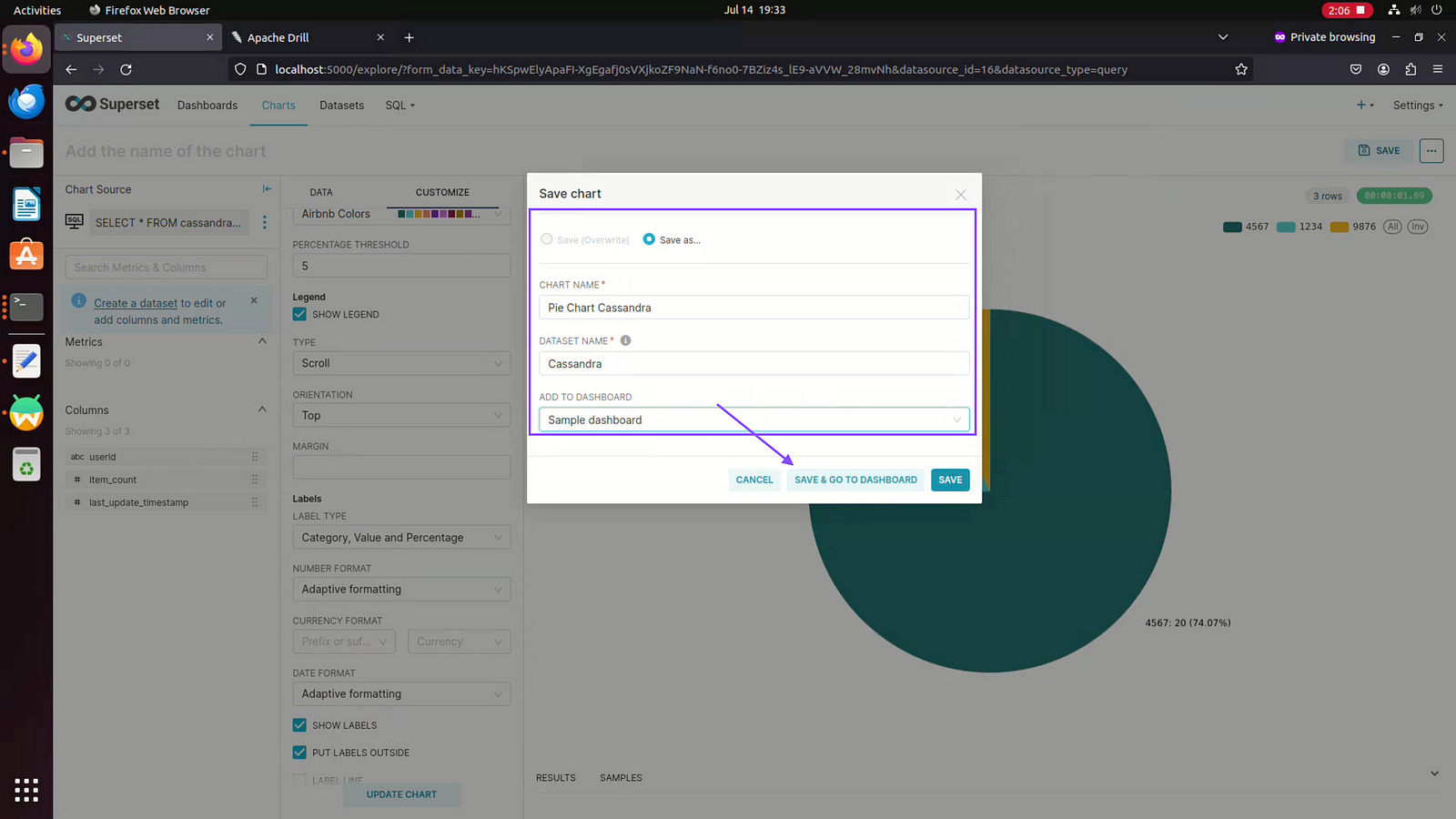
Step 16: Click on save chart

Step 17: Enter the chart name , Dataset Name, Sample Dashboard and then click on save and go to dashboard
Step 18: Once you reach on Dashboard Page then resize the chart and click on save button.

Step 19: Now can visualize Apache Cassandra with Various Apache Superset charts in similar way.

Here is youtube video for quick visual reference
